
Scaling Laws in Machine Learning
Scaling laws in machine learning, particularly in large language models (LLMs), describe how model performance improves as you increase resources like model parameters, dataset size (tokens), and compute power. These laws help determine the most efficient way to scale models to maximize performance while minimizing costs.
In deep learning, scaling laws suggest that error rates (loss) follow a predictable power-law decline as models are trained with more compute, parameters, or data. However, the improvement is not linear, meaning you get diminishing returns as you scale.
In this blog post, I will explain and visualize the relationship among LLM token size, parameter size, and performance (measured in MMLU) to help demystify the impact of scaling on model efficiency, showcase optimal training strategies, and provide insights into the trade-offs between model size, data quantity, and computational resources.
1. Parameter Size vs. Performance (MMLU)
- Generally, larger parameter sizes (e.g., billions or trillions of parameters) tend to correlate with higher performance on MMLU (Massive Multitask Language Understanding).
- More parameters allow a model to capture richer and more complex representations of language, leading to better generalization.
- However, scaling laws suggest diminishing returns — doubling parameters does not necessarily double MMLU performance.
- Training efficiency and architectural improvements (e.g., MoE, better optimizers) can make smaller models perform comparably to larger ones.
2. Token Size vs. Parameter Size
- Token size refers to the number of tokens trained on, which determines the amount of knowledge a model learns.
- A higher token-to-parameter ratio often improves efficiency — if a model is too large but trained on too few tokens, it may overfit or underperform.
- Empirically, optimal token-to-parameter ratios for transformers tend to be in the range of 10:1 to 20:1 (tokens:parameters).
- Models with excessive parameters but insufficient tokens may fail to generalize well.
3. Token Size vs. MMLU Performance
- MMLU evaluates a model’s factual and reasoning abilities across domains. Increasing token size during pretraining improves factual recall and reasoning.
- More tokens lead to better world knowledge, memorization, and zero-shot capabilities.
- However, there is also a saturation point — beyond a certain number of tokens, additional training provides marginal MMLU gains.
- High-quality, diverse datasets (rather than just more tokens) can significantly boost performance.
4. Balancing All Three Factors
- Under-trained models: Large parameters with too few tokens → Poor generalization.
- Over-trained models: Too many tokens on small parameters → Computationally inefficient.
- Optimally trained models: A balanced parameter-to-token ratio with proper dataset diversity and quality leads to the best MMLU performance.
OpenAI’s GPT models, DeepMind’s Chinchilla, and Meta’s Llama models have highlighted that optimal training scales matter more than just increasing parameters.
Chinchilla scaling laws suggest that instead of scaling parameters alone, models should increase tokens proportionally for efficiency and performance.
5. Scaling Trends in LLMs: A Visual Comparison of Major Models
This scatter chart illustrates the scaling trends among major LLMs, with the x-axis representing model parameters, the y-axis indicating the number of training tokens, and bubble size corresponding to MMLU performance. This visualization helps reveal how different models balance size and data to achieve optimal performance.
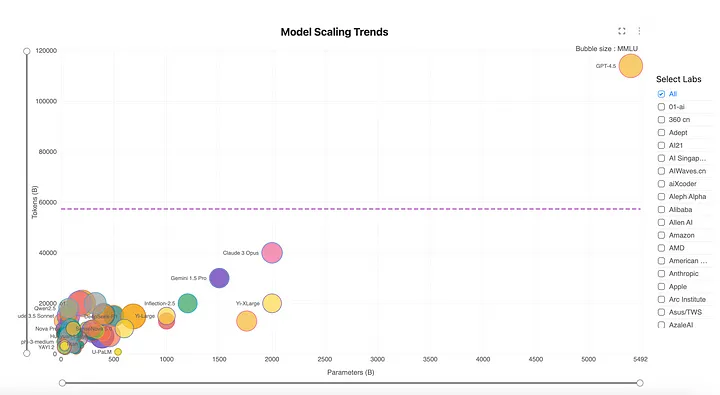
As seen in the chart, models with a higher token-to-parameter ratio tend to achieve better MMLU scores, suggesting that efficient training strategies — rather than just increasing parameter count — play a critical role in overall performance.
Larger bubbles positioned towards the upper-right corner indicate models that have successfully leveraged both large-scale training data and optimized parameter sizes, whereas smaller bubbles suggest suboptimal scaling strategies.
This visualization highlights the trade-offs in LLM development, showcasing how increasing parameters without proportionally increasing training tokens can lead to inefficiencies, while well-balanced models achieve superior performance.
This interactive chart is created and hosted at OPTIMIBI. Feel free to play around with it yourself!
6. Final Takeaway
To achieve higher MMLU scores, bigger isn’t always better. Balancing is the key:
- Balance parameter size and token count (optimal token-to-parameter ratio).
- Ensure diverse and high-quality training data.
- Optimize architectures (MoE, better training objectives) for efficient scaling.
